What do we mean by Self-Serve
Self-serve, or self-service, has been around in various guises for decades from Automatic Teller Machines (ATMs) through to self-serve analytics. With the advent of spreadsheeting tools, self-serve analytics has arguably been around for a long time, and with the more recent introduction of dedicated self-serve Business Intelligence tools, self-serve has become embedded in the analytics vernacular.
But what do we really mean when we say “self-serve”? In my experience, we all have different interpretations and understanding of what we mean - and those interpretations will be specific to the context in which we operate. For some, self-serve could mean allowing the end-user to author their own reports. For others, it could mean allowing the end-user to be fully involved in the onboarding, curation and sharing of data.
Let’s start with an analogy
Sometimes it can be easier to convey ideas and concepts using analogies, so let’s use one. The most obvious analogy to use is that of restaurants and cooking. We’re all familiar with the concept of a restaurant, and we all know that a restaurant is a place where we can be served a limited choice of food. But there are different types of restaurants which cater for different styles of service. From traditional, sit-down restaurants through to cook-your-own food restaurants.
Sit-down Restaurants
Sit-down restaurants are restaurants where the customer is seated at the restaurant and is served their food from a restricted menu. The preparation of the food is done by the professional kitchen staff, the food is served by professional waiting staff and all the customer has to do is choose what they want to eat.
If we translate that to analytics, we can say that all the end-user has to do is choose which report they want to look at and consume. Everything else is handled by the system and the data professionals in the background.
Conveyer Belt Restaurants
Conveyer Belt Restaurants are prevalent in Japan and are making headway in the western world. Food is prepared by professional kitchen staff, but here the customer is served the food from a conveyer belt. There’s no waiting staff to serve them. The customer chooses what they want to eat based on what they see on the conveyer belt. The menu is still fairly restricted but the customer has flexibility in being able to choose what to eat when they’re ready.
If we translate that to analytics, this could be an end-user creating their own reports. All the hard work is done for them, they’re choosing visuals based on the data made available to them.
Buffet Restaurants
Buffet Restaurants have a wide range of options, usually across cultures and regions. The customer serves themselves from the buffet and the menu is fairly unrestricted. Food is still prepared by the professional kitchen staff, but the customer has a choice of what they want to eat and how to compose their own menu. For example, they could choose to have dessert on the same plate as their main meal. Most people would be horrified at the pairing of desserts and main meals on the same plate, but the buffet is a great way to get a taste of the world in a manner that suits individuals.
Translating that to analytics, and this is end-users creating their own semantic data models. The preparation of data is still done by other people, but the end-user has the ultimate choice and decision about how that data model is constructed, what data goes into it and what it is visualised in the reports. This is the traditional remit of self-serve analytics tools, like Power BI, and is typically seen as the limit to self-serve analytics.
Cook-Your-Own Food Restaurants
Cook-your-own food restaurants are fairly limited to Japan and Korea, but we’re seeing more and more of them in the west. As a result of the Covid-19 Pandemic, many sit-down restaurants pivoted to a cook-your-own offering in the shape of restaurant kits. In a cook-your-own food restaurant, the customer is given prepared ingredients and is then left to cook their own food. There are usually hot plates in front of the customer for the customer to cook the food on.
Back in the analytics world, this would be allowing the end-user to curate their own data, and present it in their own way. We’re pushing the responsibility of curating data to the end-user and away from the data professionals. The professionals are still involved in preparing the data to the end-user, but the end-user is now responsible for curating the data and presenting it in a way that is meaningful to them.
Prep and Cook at Home
Ok, this is perhaps not a restaurant any more. There perhaps aren’t any customers. But here, the “customer” is preparing and cooking the food themselves. There are no kitchen staff, waiting staff. The “customer” is entirely responsible for the food and the way it is cooked. They might follow a recipe, they might not. This is the preserve of the generalist. The amateurs are in control. But this doesn’t mean that the food will be ugly and bland - “Not everyone can become a great artist; but a great artist can come from anywhere.”1
In analytics, this would mean the end-user is fully involved in the onboarding and ownership of analytical data. Data Professionals are not involved, but might offer support and guidance.
The Recipe Creator
We’ve all scoured the internet looking for a recipe to follow, to come across an entire life story before we get to the recipe itself. Some of these recipes are great and push the boundaries of what we can do with food - contributing to the world. Others are not so great and are just a recipe. They are contributing to wider culture in establishing a new way of thinking about food.
With analytics, this would be end-users contributing to best practice and the wider data culture. We’re blurring the lines between traditional data professionals and end-users. The generalist is the professional, the specialist is the end-user.
Self-Serve Analytics
We’ve explored the analogy above, and mapped the different self-serve levels to the different types of restaurants. Now let’s look at the different self-serve levels in more detail.

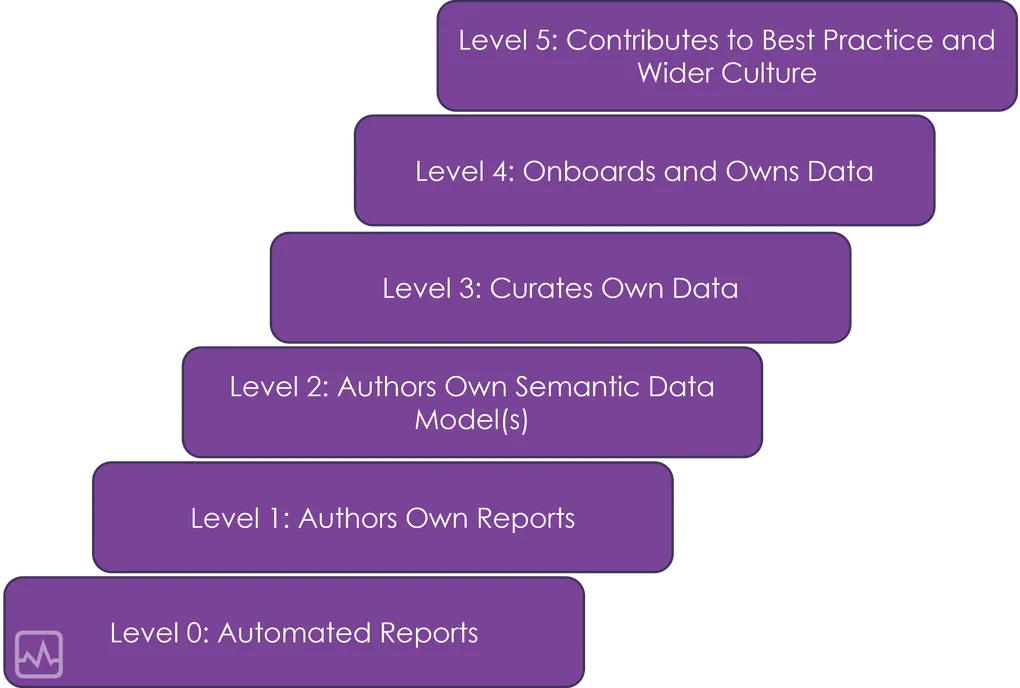
Level 0: Automated Reports
This is traditional analytics. From an analytics maturity curve perspective, this is most immature level of analytics. End-users are spoonfed data and often told how to interpret the data. This assumes that there are fixed views of data that are defined and maintained by data professionals. If the end-user has any choice in how they interact with the data, it’s either through pre-defined slicers (if they exist) or they can choose a different report.
As it is the most rigid form of analytics, it also creates the most contention and friction between the end-user and the data professionals. The anecdotal stories we have of end-users getting frustrated having to wait weeks or months for a report to be generated, and the frustration of data professionals with the end-users for not having any understanding or appreciation of the complexities of the requirements or the skills required to produce the reports.
And we have this frustration from both sides, resulting from the fact that the end-user has no ownership of the data.
Level 1: Authors Own Reports
In an attempt to address the lack of ownership of the data, we’ve got a slightly more mature new level of analytics, in which end-users author their own reports from centralised data models. They have flexibility in choosing what data they want to visualise and how to interpret it. However, they are still dependent on the data professionals, who have ultimate ownership of the data model.
However, there can still be frustration from the end-user and the data professionals. From the end-user, if they want new data or calculations in the model, they’re still dependent on the data professionals. From the data professionals, it still takes a lot of time and effort to update the data model. But, because we’ve shifted more ownership and responsibility from the data professionals to the end-user, both parties are likely to be less frustrated than they were before.
Level 2: Authors Own Semantic Data Model(s)
Further addressing frustrations with lack of ownership of data, this maturity level is encapsulated by the remit of self-serve analytics tools, like Power BI, and is typically seen as the limit to self-serve analytics. End-users are responsible for creating their own semantic data models, calculations, visualisations and interpretations of data. The preparation and curation of data is still done by data professionals, but the end-user has the ultimate choice and decision about how that data model is constructed, what data goes into it and what it is visualised in the reports.
End-users are still dependent on data professionals for the application of business logic to the data, so that it can be consumed and modelled in a way suitable for the end-user - so if they need to bring in new data to the model, they’re still dependent on the data professionals. Of course, there are methods available to end-users to bring in their own data, circumventing the need for data professionals, but this isn’t necessarily the best way to do it.
With this level of self-serve analytics, the end-user requires training and guidance from the data professionals to understand the tools and techniques they can use to create their own data models, as well as understanding what data is available to them, the provenance and quality of the data. With this transference of responsibility and ownership of data, also needs to come with a transference of skills and expertise, so that the end-user is empowered to create value from their data.
Is there less frustration and friction between the end-user and the data professionals? Certainly a lot less than before, but where there is dependency there will always be friction.
Level 3: Curates Own Data
Shifting the responsibility further on to the end-user, this level of self-serve analytics where there’s a lot more blending of responsibilities and roles between end-user and data professional. This area of data is traditionally the preserve of BI developers and the emerging role of Analytics Engineers - transforming cleansed source data into curated assets through the application of business logic. With this level, end-users are fully responsible for curating their own data and applying business logic to the data. They are not dependent on data professionals for the curation of the data, but they are still dependent for the onboarding and cleansing of data.
This feels like a natural limit for self-serve analytics, while we’re still in the realms of monolithic and centralised data architectures, such as data lakes, data warehouses, data lakehouses and so on. If we’re to shift the ownership of data further on to the end-user, we need to be able to do this without the need for data professionals and, in so doing, without the need for a centralised data platform.
Level 4: Onboards and Owns Data
Now we’re in the realm of distributed, decentralised data architectures of the Data Mesh, and similar. The end-user is fully responsible for onboarding and ownership of their data. Data professionals no longer exist and have evolved into supporting a self-serve data platform. This data platform enables self-serve to encompass all facets of data - from onboarding and ingestion, through cleansing, modelling and serving.
For more information on the self-serve data platform, see this blog post on a deep dive into data mesh.
Level 5: Contributes to Best Practice and Wider Culture
If we’ve got this far, we’ve got a solid understanding of the different self-serve levels. This last one might appear to be unattainable, but it’s the level of self-serve analytics that is the most important and doesn’t require any of the other levels to be achieved.
In this level, we still have end-users and data professionals, but some sections of end-users have evolved into extolling the value of the data, and contributing to how the organisation should use data in the form of best practice guidance and encouraging a positive data culture in the wider organisation.
Conclusion
We’ve explored the different self-serve levels in more detail, and we’ve seen how they impact the way end-users and data professionals interact with each other. By shifting more responsibility and ownership towards the end-user, we’re reducing friction. But at the same time, the end-users need to be empowered to create value from their data through training and guidance from the data professionals.
We’ve also seen how varied the definitions for self-serve analytics are, and how we need to be clear on what we mean by self-serve analytics, as self-serve can be defined in different ways.
For organisations, it’s important to understand the different self-serve levels - recognise where they are and where they want to be - so that they can plot how to achieve their target self-serve level.
Footnotes
-
Anton Ego, Ratatouille (2007) ↩